# 查询示例(自动提取图中所有表格数据)
在CAD图中自动识别并导出表格数据,是相关领域数据处理的重要需求。由于CAD图形并不像传统的电子表格那样具备明确的行列关系,表格常以线条和文本形式存在,手动提取不仅费时费力,还容易出错。如何通过自动化工具通过图形解析快速、高效地识别表格结构,提取数据并导出至Excel、CSV等格式,已经成为提高工作效率的关键。以下是几种常见的方法:
# 常用方法
# 1. 基于图形对象解析的方法
在CAD图中,表格通常由水平和垂直的直线或其他几何图形构成,其核心思想是通过解析这些图形对象,推断表格的结构。
主要步骤:
- 对象提取:使用相关工具提取CAD文件中的几何对象。通常,水平和垂直线的组合会形成表格的边框,文本对象则表示表格的内容。
- 结构识别:通过检测平行和垂直直线的排列模式来确定行列分布。通常可以通过计算直线之间的间距及其交叉点,判断其是否组成了表格的单元格。
- 文字匹配:识别并匹配每个单元格内的文字,通常通过坐标位置和表格框架的对应关系来确定文本的归属。
优点:
- 对表格结构明确、规则的CAD图具有较高的准确性。
- 适用于可编程的场景,能针对大批量的CAD文件进行自动处理。
局限性:
- 处理复杂、不规则表格时,可能难以自动识别正确的行列关系。
- 需要一定的编程和CAD知识。
# 2. 使用AutoCAD内置的表格对象(Table Object)
自AutoCAD 2005版本起,CAD引入了专用的表格对象(Table),这是识别和导出表格数据的另一条有效路径。AutoCAD的表格对象类似于Excel中的表格,具备明确的行、列结构及单元格内容。
主要步骤:
- 直接读取表格对象:通过AutoCAD的API(如AutoCAD .NET API或ObjectARX),可以直接读取表格对象,获取行、列信息,以及每个单元格的文本、数值等内容。
- 数据提取与导出:基于这些API,用户可以轻松将表格内容导出为CSV、Excel等常见的表格文件格式,便于后续的数据分析和处理。
优点:
- 操作简便,表格对象的结构化数据便于直接提取。
- 对于表格对象较为标准的CAD文件,识别精度高。
局限性:
- 仅适用于含有AutoCAD内置表格对象的图纸,无法处理手动绘制的表格。
# 3. 使用OCR(光学字符识别)技术
对于某些复杂或非标准的表格,特别是手动绘制的表格,图形对象的解析可能存在较大挑战。在这种情况下,OCR技术是一种有效的替代方案。OCR能够从图像中识别出文字,并通过算法还原表格结构。
主要步骤:
- 图像转换:首先,将CAD图导出为高分辨率的图像格式(如PNG、TIFF)。这些图像能更好地呈现表格中的文字和边框。
- OCR识别:使用OCR软件对图像中的文字和表格线条进行识别。部分高级OCR工具可以自动识别表格行列,恢复数据的矩阵结构。
- 数据导出:OCR工具通常可以直接将识别到的表格导出为Excel或CSV格式。
优点:
- 对于复杂的手工绘制表格,OCR技术能有效识别图像中的内容,弥补了传统CAD对象解析的不足。
局限性:
- OCR技术对图像质量有较高的要求,低分辨率的图纸可能导致识别精度下降。
- 部分表格中的内容(如特殊符号、格式)可能无法准确识别。
# 总结
利用AutoCAD内置表格对象无法处理用线条绘制出的表格的情况;OCR技术适用于图像,对于复杂的CAD图纸处理,由于干扰因素比较多,精度很差。基于图形对象解析的方法 ,尽管算法复杂,但如果能实现,则性能和效果是最佳的,也更具有通用性,能确保数据的准确性和完整性。
# 图形对象解析解析表格算法介绍
通过分析CAD文件中的几何图形(如直线、文字对象等),判断它们是否组成了表格结构,并从中提取数据。以下是实现步骤:
# 1. CAD文件读取与解析
首先,使用唯杰地图的数据查询接口 唯杰地图数据查询 (opens new window),查询图中所有的直线、多段线、二维多段线、三维多段线、单行文本、多行文本对象。如果使用内存直接打开的话,可以使用后台表达式查询 (opens new window)图中所有的对象实体。
# 2. 几何对象的提取与分类
典型的表格是由水平和垂直的直线构成,因此首要任务是筛选出这些直线对象。对于较复杂的图形,可能还需要筛选出多段线或矩形。如果多段线来表示单元格边框,则需要先将其分解为简单的线段。
在提取直线时,需获取其几何参数,包括起点和终点的坐标。对于每个直线对象,记录其方向(水平或垂直)、长度、位置等参数。此外,提取表格内的文本对象,通过文本的插入点坐标与表格框架的相对位置,确定其所在的单元格。
# 3. 表格框架的识别
表格的框架通常由交叉的水平线和垂直线组成。识别表格框架的核心在于检测这些直线是否形成了规则的行列布局。具体步骤如下:
- 水平线和垂直线的区分:通过计算直线的斜率或起点、终点的相对位置,判定直线是水平线还是垂直线。
- 线段聚类:将相互平行、间隔距离接近的线段分为一组。例如,所有水平线可按Y坐标排序,将Y坐标接近且在容差范围内的线段归为同一行。同样地,对垂直线按X坐标进行聚类,形成列结构。
- 交点计算:通过水平线和垂直线的交点,确定表格的每个单元格的边界。这些交点是表格的关键节点,构成了单元格的顶点。
通过查看相关论文,在一篇<<表格识别中的算法改进>>论文中介绍的通过特征点识别表格边框帮助很大。
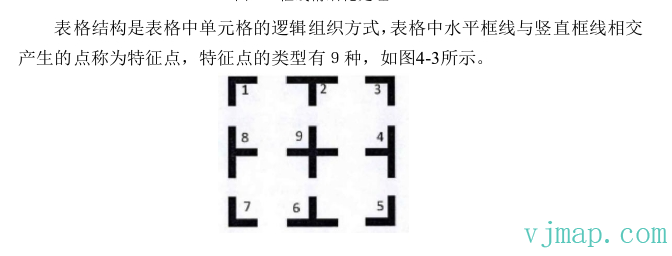
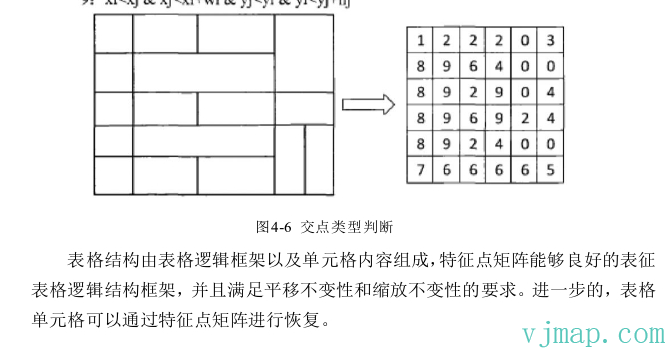
# 4. 单元格结构的提取
在识别出表格的框架后,可以通过水平线和垂直线的交点来确定每个单元格的边界。每个单元格的范围由相邻水平线和垂直线的交点定义。需要特别处理线条缺失的情况,例如某些手动绘制的表格可能不完整,部分边界线缺失,这时需要通过推测和补全技术来弥补边界的缺失。
# 5. 文本与单元格的关联
表格中的核心数据通常以文本形式存在。文本对象通常具有插入点坐标、字体信息以及文本内容。为了将文本与表格中的单元格正确关联,需要将每个文本对象的插入点与之前识别出的单元格范围进行比较,确定其所属的单元格。可以采用以下方法:
- 坐标匹配:通过检查文本插入点是否位于某个单元格的边界内,将该文本归属到该单元格中。由于文本插入点可能位于单元格的不同位置(如左下角或中心),需根据文本对齐方式进行调整。
- 多文本处理:如果一个单元格中包含多个文本对象,则需要将这些文本内容合并为单一数据,或根据特定规则进行分隔和处理。
# 6. 合并单元格的识别与处理
合并单元格是表格中常见的复杂情况。通过检查相邻单元格是否共享相同的边界线,可以识别合并单元格。具体而言,如果某些行或列的线条缺失且相邻单元格的内容一致,则可以判断它们是合并单元格。处理时,将合并单元格的内容统一保存,并调整其输出形式,以确保数据的一致性。
# 7. 优化与异常处理
在表格解析的过程中,还需考虑一些可能的异常情况:
- 线条断裂或不连续:CAD图中的线条可能由于绘制精度问题而存在细微的断裂,识别时需要设置一定的容差值来处理这些异常情况。
- 复杂图形混淆:有时图纸中会包含其他几何形状或注释,它们可能干扰表格的识别。通过采取对象筛选的方法,仅处理与表格相关的几何对象。
# 实现效果
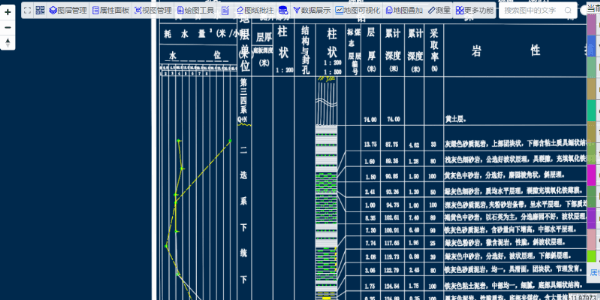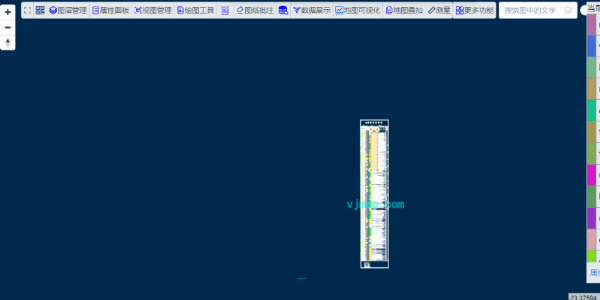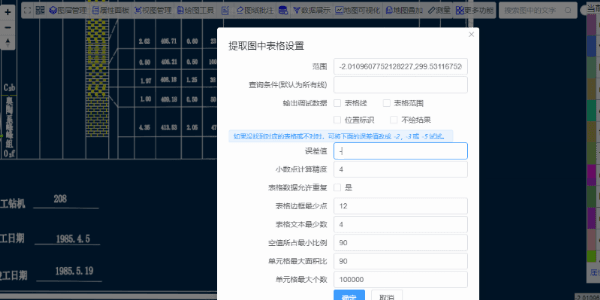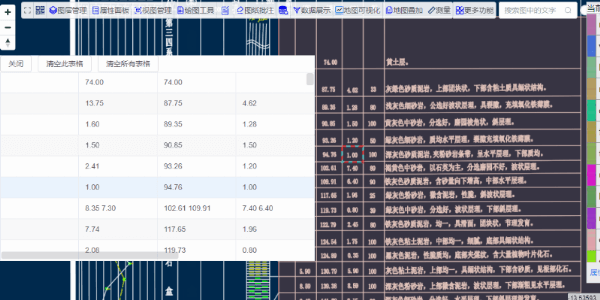
在唯杰地图管理云平台 (opens new window) 上传要提取表格的CAD图形,成功打开后,点击“更多功能”里面的“自动提取图中所有表格”
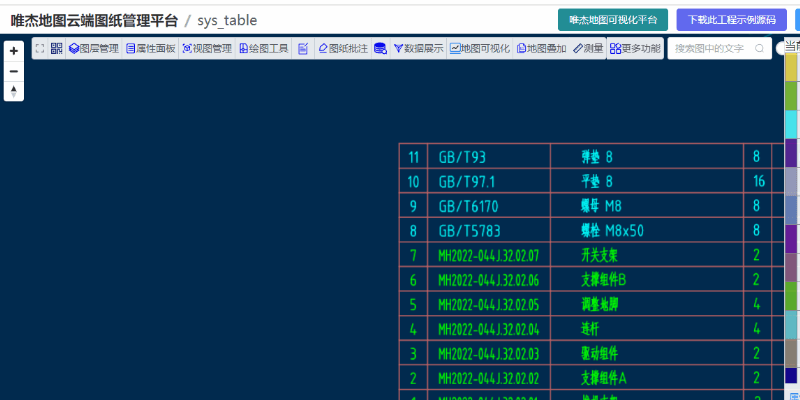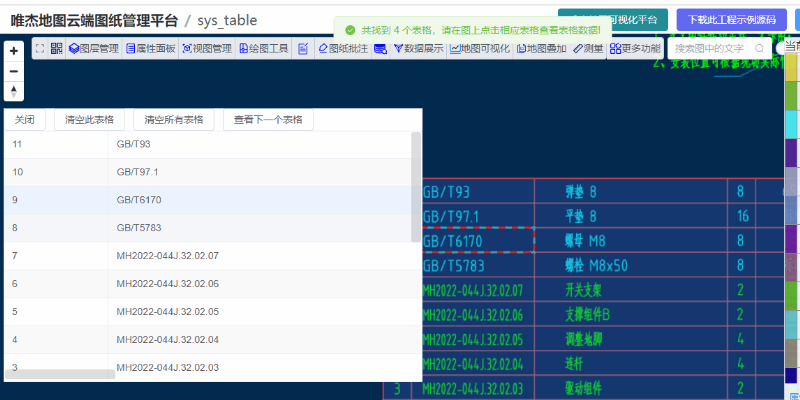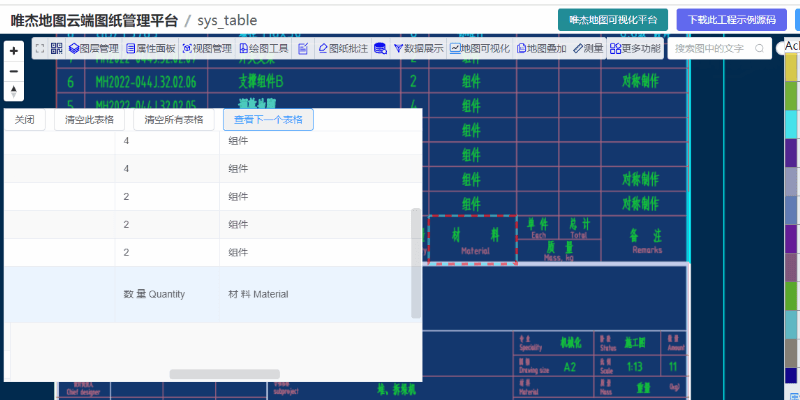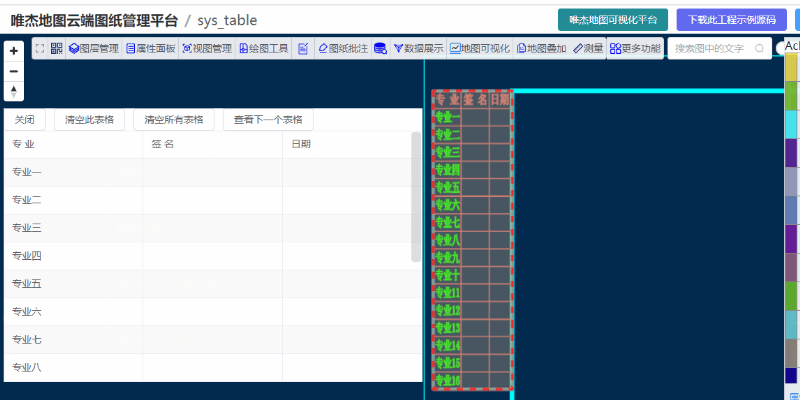
对于一些复杂的图形或有误差的图形,可适当的增大误差值或“选择区域手动提取表格数据”
提出的数据是后台返回表格数据的json格式,示例中用table组件做了展示。如果需要把数据导出为excel或csv格式,可以基于此示例(此示例已开源)完善下即可。
在唯杰地图中表格特征点用如下值表示,可以设置界面里面点击调试输出“位置标识”进行查看调试。

接口文档:
/**
* 自动提取图中表格参数
*/
export interface IExtractTable {
/** 地图ID. */
mapid?: string;
/** 地图版本(为空时采用当前打开的地图版本). */
version?: string;
/** 图层样式名.为空时,将由选择的实体的图层来决定 */
layer?: string;
/** 范围 [x1,y1,x2,y1] 为空表示此个图,否则为指定区域查询提取. */
bounds?: string;
/** 查询条件(默认为所有线). */
condition?: string;
/** 是否输出调试数据. */
debug?: boolean;
/** 小数点计算精度. 正数表示精度为小数点后几位,负数表示精度为小数点前几位 默认为4 */
digit?: number;
/** 误差值. 正数表示距离小于这个误差值就以为是直线(为零的话表示自动求误差值),负数表示自动获取的误差值比例倍数大小 默认为0自动*/
tol?: number;
/** 表格边框最少点. 如果表格边框点数小于这个数将排除此表格. 默认 12*/
tableEdgeMinPoint?: number;
/** 表格文本最少数. 如果表格中所有文本个数小于这个数将排除此表格. 默认 4*/
tableTextMinCount?: number;
/** 单元格最大面积比.单元格面积占整体表格面积的比例不能超过这值,超过了此值,将不获取内容 . 默认 90*/
cellMaxArea?: number;
/** 空值所占最小比例. 空值占所有表格的比例超过此值将排除此表格. 默认 90*/
cellEmptyRatio?: number;
/** 单元格最大个数 允许的单元格最大个数,超过这值将排除此表格 . 默认 100000 */
tableMaxCellCount?: number;
/** 线段中允许折线段数 默认情况下只提取水平线或垂直线,如果要允许折线,设置允许线段中折线的段数(非水平和垂直线段) . 默认 0 */
noHvLineSegCount?: number;
/** 表格数据允许重复. 表格数据允许重复会尽可能搜索多的表格,但同一份数据可能在不同的表格中 默认false */
seachTableMost?: boolean;
/** 查找子图范围 默认false */
findChildMapRects?: boolean;
}
/**
* 自动提交图中的表格
* @param param 参数
* @return {Promise<any>}
*/
async cmdExtractTable(param: IExtractTable)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 扩展应用
在之前介绍的自动分割子图 (opens new window)的算法是在前端实现的,如果把上面提取表格的算法稍改进下,也可以应用于获取所有子图范围。
可需要把上面接口文档的中的findChildMapRects设置为true,即可获取所有子图范围。再调用拆分子图的功能即可。
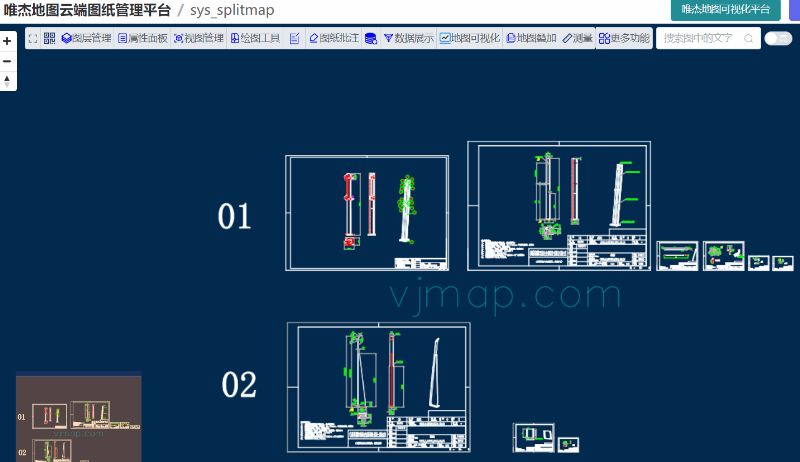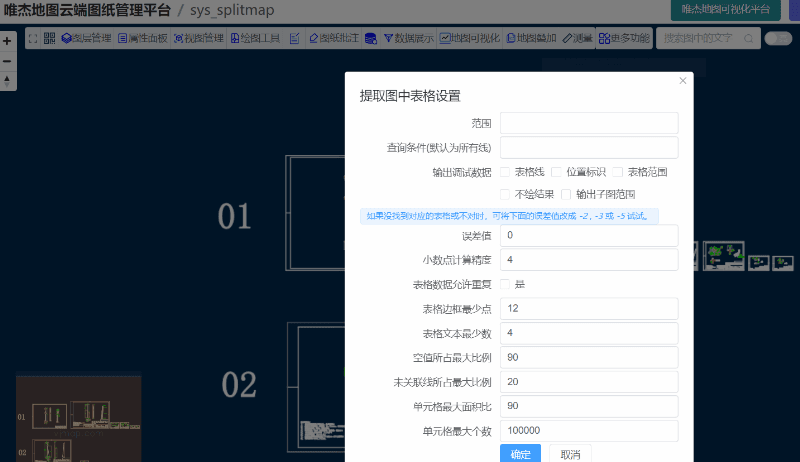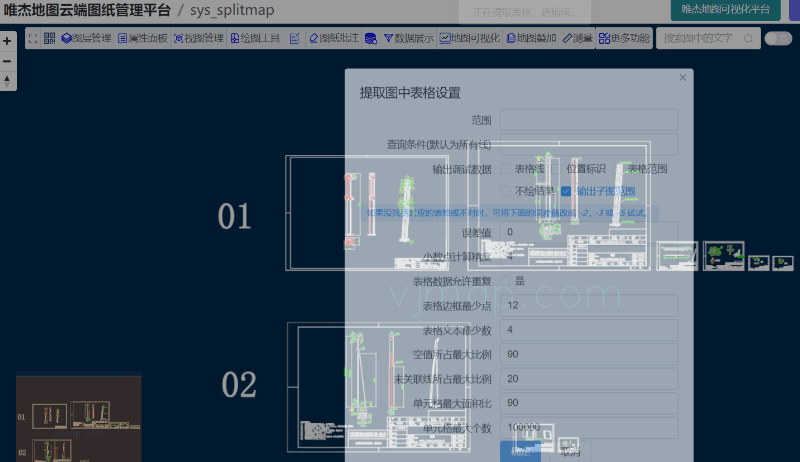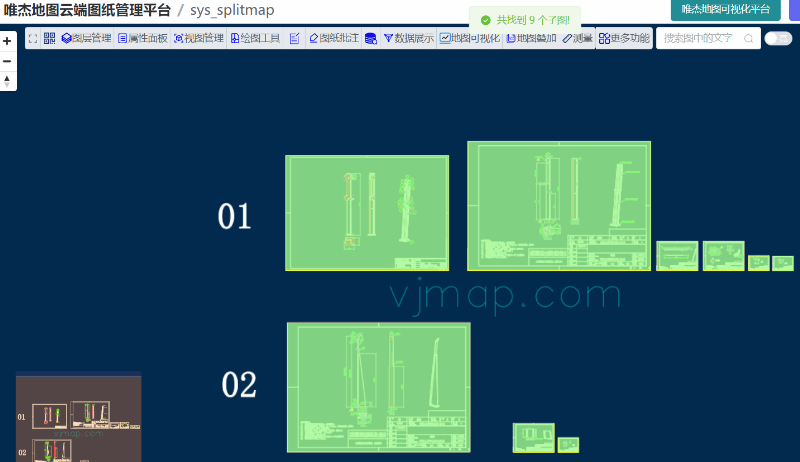
/**
* 拆分子图参数
*/
export interface ISplitChildMaps {
/** 地图ID. */
mapid?: string;
/** 文件ID. (有mapid,优先使用mapid,没有mapid,使用fileid) */
fileid?: string;
/** 地图版本(为空时采用当前打开的地图版本). */
version?: string;
/** 每个子图拆分后是否全图. 默认false */
isFullExtent?: boolean;
/** 子图范围数组. ["x1,y1,x2,y2", "x1,y1,x2,y2", ...] */
clipBounds: string[];
/** 方法 cloneObjects 通过深度克隆实体,效率最快(默认), cloneDb 通过克隆文档数据库,效率较快;cloneMap 通过克隆图,效率较慢,但最能保持原样*/
method?: "cloneObjects" | "cloneDb" | "cloneMap";
/** 是否启动新进程处理(不影响主进程,看初始速度慢些) 默认true */
startNewProcess?: boolean;
}
/**
* 拆分子图
* @param param 参数
* @return {Promise<any>}
*/
async cmdSplitChildMaps(param: ISplitChildMaps)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
拆分子图在线示例 https://vjmap.com/demo/#/demo/map/service/22findsubmapsplit2 (opens new window)